

Table of contents
The context behind payment failures
When a customer attempts to pay and the payment fails, the reason is usually outside the merchant’s control: for example, insufficient funds, decisions made by the issuing bank, or technical issues on the processor’s side. These are inevitable scenarios in any payment system.
What does depend on the business is how to respond when these payment errors occur. High-volume merchants, especially those working with orchestration, know they can define alternative routes for these cases: fallback routes that are automatically triggered when a processor fails.
However, adding a fallback to a payment setup can be complex: you need to define when the route should be executed, how many attempts should be made within the same payment, as well as implement the changes. All of this involves configurations that can create operational errors.
From Zru’s product team, we have worked on how to approach fallbacks so they add value to business operations, without introducing friction or complexity when changes are needed.
We see fallbacks as more than simple retries
It is common to limit fallbacks to a binary rule: if one provider fails, charge through another.
However, that logic can fall short because it is too generic and does not take into account the real context of each payment.
At Zru, we see every day that not all payment failures mean the same thing, and not all retries add value to the merchant.
The most obvious cases are “final” errors, such as “insufficient funds” or “expired card.” In these situations, we should not continue attempting the payment through another processor, as it will return the same error.
But variables such as the time, the day of the week, the card type, the card’s country of issuance, or even the payment amount must also be taken into account. Since every business has its own particularities, there are times when even if the payment is retried, it will not succeed.
We believe it is important for businesses to first understand their operations, be clear about when it makes sense to attempt the payment through another processor, and create routes based on what they know. To truly understand their operations, it is often necessary to first validate hypotheses, and this involves creating fallbacks in an agile way: adding, modifying, and removing routes whenever needed, without relying on the development team and without putting the entire operation at risk.
The design decision: fallback logic within orchestration
From the beginning, we were clear that fallbacks could not be treated as an isolated feature or as a simple chain of independent rules. Failures are part of the normal behavior of a payment system, and designing them as something exceptional would be a mistake.
That is why we decided to integrate fallback logic directly into the orchestration layer. Treating failure as just another part of the flow allowed us to design fallback logic as a natural extension of how transactions are routed and processed.
From this perspective, fallback logic had to be capable of capturing decisions that payments teams already make in practice, even if often implicitly or reactively. For example:
When it makes sense to retry a payment and when insisting only adds operational noise.
Which alternative route to apply on a second attempt, depending on the payment context.
When to stop retries to avoid loops or accumulating failures that could harm the relationship with a provider.
How does fallback logic work?
Within the same orchestration, you can define as many fallbacks as make sense in each case, and each one runs independently within the flow.
Each fallback is executed, or not, based on explicit conditions defined from the payment’s own variables. These variables are what the system uses to apply the logic defined by the payments team and execute a retry only when it makes sense.
Conditions can be built, for example, based on:
Transaction variables, such as currency, amount, transaction type, whether the transaction is MOTO…
Customer variables, such as device type or certain identifying information.
Card variables, such as card type, brand, or country of issuance.
Custom variables defined by the merchant according to their operations.
This approach ensures that a fallback stops being an automatic retry and is only executed when the conditions defined by the business’s operations justify it. For example, retrying only during the first days of the month or only for recurring transactions.
Another option is to differentiate behavior based on the card’s origin. If the card is European, the fallback can route to a specific provider; if it is from the United States, to a different one; and if it meets neither condition, no fallback will be executed.
Designing fallback logic this way allows the system to act as the payments team would “in real time,” rather than as a generic rule applied to all cases. It is not about always retrying, but about deciding when it makes sense to do so and when it does not, and embedding that decision into the orchestration from the very beginning.
With this approach, decisions about fallbacks no longer depend on technical backend changes. The logic lives within the orchestration layer and can be adjusted directly by the payments team as operations evolve, without modifying code.
In this way, payments teams can make adjustments to fallback logic quickly. Not only because the fallback logic is “more flexible,” but because it is designed so that these types of adjustments are part of normal operations rather than an exceptional process.
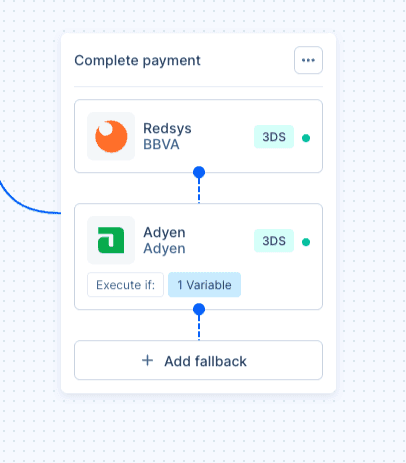
Fallback in practice
Let’s imagine an ecommerce business in Spain that works with two processors. The first applies a variable fee (a percentage of the cart value), and the second, in addition to the percentage, charges a fixed fee per transaction of X cents.
The company defines its orchestration as follows: card payments are first sent to processor 1 and, if they fail, are automatically retried through processor 2.
However, since processor 2 charges a fixed fee (in addition to the variable one), for low-value orders, for example below €10, this fixed cost may make the retry unprofitable. In those cases, insisting with the second processor does not make sense.
For that reason, the fallback can be configured to trigger only when the order is equal to or greater than €10. This way, the logic is not applied indiscriminately but aligned with the real profitability of each transaction.
These types of rules are configured directly from the Zru dashboard, without the need for code.
If you’d like to learn more about how we can support your day-to-day payment operations, our team at Zru will be happy to assist you.
Table of contents
The context behind payment failures
When a customer attempts to pay and the payment fails, the reason is usually outside the merchant’s control: for example, insufficient funds, decisions made by the issuing bank, or technical issues on the processor’s side. These are inevitable scenarios in any payment system.
What does depend on the business is how to respond when these payment errors occur. High-volume merchants, especially those working with orchestration, know they can define alternative routes for these cases: fallback routes that are automatically triggered when a processor fails.
However, adding a fallback to a payment setup can be complex: you need to define when the route should be executed, how many attempts should be made within the same payment, as well as implement the changes. All of this involves configurations that can create operational errors.
From Zru’s product team, we have worked on how to approach fallbacks so they add value to business operations, without introducing friction or complexity when changes are needed.
We see fallbacks as more than simple retries
It is common to limit fallbacks to a binary rule: if one provider fails, charge through another.
However, that logic can fall short because it is too generic and does not take into account the real context of each payment.
At Zru, we see every day that not all payment failures mean the same thing, and not all retries add value to the merchant.
The most obvious cases are “final” errors, such as “insufficient funds” or “expired card.” In these situations, we should not continue attempting the payment through another processor, as it will return the same error.
But variables such as the time, the day of the week, the card type, the card’s country of issuance, or even the payment amount must also be taken into account. Since every business has its own particularities, there are times when even if the payment is retried, it will not succeed.
We believe it is important for businesses to first understand their operations, be clear about when it makes sense to attempt the payment through another processor, and create routes based on what they know. To truly understand their operations, it is often necessary to first validate hypotheses, and this involves creating fallbacks in an agile way: adding, modifying, and removing routes whenever needed, without relying on the development team and without putting the entire operation at risk.
The design decision: fallback logic within orchestration
From the beginning, we were clear that fallbacks could not be treated as an isolated feature or as a simple chain of independent rules. Failures are part of the normal behavior of a payment system, and designing them as something exceptional would be a mistake.
That is why we decided to integrate fallback logic directly into the orchestration layer. Treating failure as just another part of the flow allowed us to design fallback logic as a natural extension of how transactions are routed and processed.
From this perspective, fallback logic had to be capable of capturing decisions that payments teams already make in practice, even if often implicitly or reactively. For example:
When it makes sense to retry a payment and when insisting only adds operational noise.
Which alternative route to apply on a second attempt, depending on the payment context.
When to stop retries to avoid loops or accumulating failures that could harm the relationship with a provider.
How does fallback logic work?
Within the same orchestration, you can define as many fallbacks as make sense in each case, and each one runs independently within the flow.
Each fallback is executed, or not, based on explicit conditions defined from the payment’s own variables. These variables are what the system uses to apply the logic defined by the payments team and execute a retry only when it makes sense.
Conditions can be built, for example, based on:
Transaction variables, such as currency, amount, transaction type, whether the transaction is MOTO…
Customer variables, such as device type or certain identifying information.
Card variables, such as card type, brand, or country of issuance.
Custom variables defined by the merchant according to their operations.
This approach ensures that a fallback stops being an automatic retry and is only executed when the conditions defined by the business’s operations justify it. For example, retrying only during the first days of the month or only for recurring transactions.
Another option is to differentiate behavior based on the card’s origin. If the card is European, the fallback can route to a specific provider; if it is from the United States, to a different one; and if it meets neither condition, no fallback will be executed.
Designing fallback logic this way allows the system to act as the payments team would “in real time,” rather than as a generic rule applied to all cases. It is not about always retrying, but about deciding when it makes sense to do so and when it does not, and embedding that decision into the orchestration from the very beginning.
With this approach, decisions about fallbacks no longer depend on technical backend changes. The logic lives within the orchestration layer and can be adjusted directly by the payments team as operations evolve, without modifying code.
In this way, payments teams can make adjustments to fallback logic quickly. Not only because the fallback logic is “more flexible,” but because it is designed so that these types of adjustments are part of normal operations rather than an exceptional process.
Fallback in practice
Let’s imagine an ecommerce business in Spain that works with two processors. The first applies a variable fee (a percentage of the cart value), and the second, in addition to the percentage, charges a fixed fee per transaction of X cents.
The company defines its orchestration as follows: card payments are first sent to processor 1 and, if they fail, are automatically retried through processor 2.
However, since processor 2 charges a fixed fee (in addition to the variable one), for low-value orders, for example below €10, this fixed cost may make the retry unprofitable. In those cases, insisting with the second processor does not make sense.
For that reason, the fallback can be configured to trigger only when the order is equal to or greater than €10. This way, the logic is not applied indiscriminately but aligned with the real profitability of each transaction.
These types of rules are configured directly from the Zru dashboard, without the need for code.
If you’d like to learn more about how we can support your day-to-day payment operations, our team at Zru will be happy to assist you.





