Producto
8
MINUTOS DE LECTURA
Cómo hemos diseñado la lógica de fallbacks en Zru


Tabla de contenido
El contexto detrás de los fallos en los pagos
Cuando un cliente intenta pagar y el pago falla, el motivo suele estar fuera del control del comercio: puede ser por ejemplo por falta de fondos, decisiones del banco emisor o incidencias técnicas del procesador. Son escenarios inevitables en cualquier sistema de pagos.
Lo que sí depende del negocio es cómo responder cuando ocurren estos errores de cobro. Los comercios con volumen, especialmente los que trabajan con orquestación, saben que pueden definir rutas alternativas para estos casos: rutas de “fallback” que se activan automáticamente cuando un procesador falla.
Sin embargo, añadir un fallback a la operativa de pagos puede ser complicado: hay que definir en qué caso se debe ejecutar la ruta, cuántos intentos se deben realizar en un mismo pago, así como implementar los cambios. Todo esto implica realizar configuraciones que pueden crear errores en la operativa.
Desde el equipo de producto de Zru, hemos trabajado sobre cómo abordar los fallbacks para que aporten valor a la operativa de los negocios, pero sin añadir fricción ni complejidad cuando se necesitan hacer cambios.
Hemos pensado los fallbacks como algo más que simples reintentos
Es corriente limitar los fallbacks únicamente a una regla binaria: si falla un proveedor, se cobra con otro. Sin embargo, esa lógica puede quedarse corta porque es demasiado genérica y no tiene en cuenta el contexto real de cada pago.
Desde Zru vemos a diario que no todos los fallos de pago significan lo mismo y no todos los reintentos van a aportar valor al comercio.
Lo más obvio son los errores “finales”, tipo “falta de fondos” o “tarjeta caducada”. En estos casos, no debemos seguir intentando el pago por otro procesador, ya que nos retornará el mismo error.
Pero también hay que tener en cuenta variables como la hora, día de la semana, el tipo de tarjeta, el país de emisión de la tarjeta, o incluso el importe del pago. Como cada negocio tiene sus particularidades, hay veces que aunque se reintente el pago, este no va a funcionar.
Nos parece importante que los negocios primero entiendan su operativa, tengan claro en qué casos merece la pena intentar el pago por otro procesador y creen las rutas en función de lo que saben. Para llegar a entender su operativa, muchas veces hay que primero validar hipótesis, y esto pasa por crear fallbacks de forma ágil: añadir, modificar y suprimir rutas cada vez que se necesite y sin depender del equipo de desarrollo y sin poner en peligro toda la operativa.
La decisión de diseño: lógica de fallback dentro de la orquestación
Desde el principio tuvimos claro que los fallbacks no podían tratarse como una funcionalidad aislada ni como una simple cadena de reglas independientes. Los fallos forman parte del comportamiento normal de un sistema de pagos y diseñarlos como algo excepcional sería un error.
Por eso decidimos integrar la lógica de fallback dentro de la propia orquestación. Tratar el fallo como una parte más del flujo nos permitió diseñar la lógica de fallback como una extensión natural de cómo se enrutan y procesan las transacciones.
Desde ese enfoque, la lógica de fallback tenía que ser capaz de recoger decisiones que los equipos de pagos ya toman en la práctica, aunque muchas veces de forma implícita o reactiva. Por ejemplo:
Cuándo tiene sentido reintentar un pago y cuándo insistir solo añade ruido operativo.
Qué ruta alternativa aplicar en un segundo intento, en función del contexto del pago.
Cuándo detener los reintentos para no entrar en bucles ni acumular fallos que perjudiquen la operativa con un proveedor.
¿Cómo funciona la lógica de fallback?
En una misma orquestación se pueden definir tantos fallbacks como tenga sentido en cada caso, y cada uno se ejecuta de forma independiente dentro del flujo.
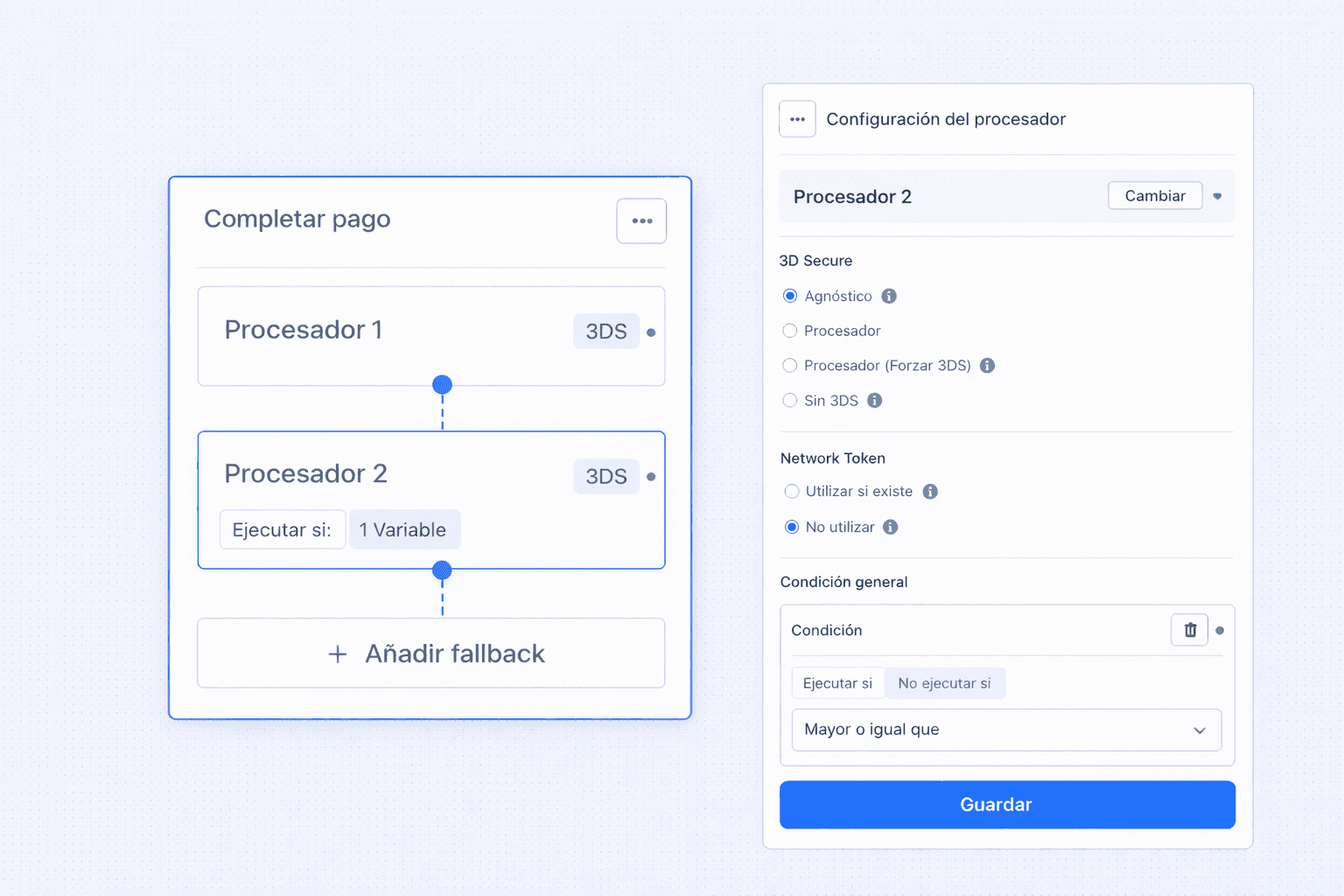
Cada fallback se ejecuta o no en función de condiciones explícitas, definidas a partir de variables del propio pago. Son esas variables las que el sistema utiliza para aplicar la lógica definida por el equipo de pagos y ejecutar un reintento solo cuando tiene sentido.
Las condiciones pueden construirse, por ejemplo, a partir de:
Variables de la operación, como la moneda, el importe, el tipo de operación, si la operación es MOTO…
Variables del cliente, como el tipo de dispositivo o cierta información identificativa.
Variables de la tarjeta, como su tipo, marca o país de emisión.
Variables personalizadas, definidas por el propio comercio según su operativa.
Este enfoque hace que el fallback deje de ser un reintento automático y pase a ejecutarse sólo cuando las condiciones definidas por la operativa del negocio lo justifican. Por ejemplo, reintentar únicamente en los primeros días del mes o solo en las operaciones recurrentes.
Otra opción es diferenciar el comportamiento según el origen de la tarjeta. Si la tarjeta es europea, el fallback puede enrutar a un proveedor concreto; si es de Estados Unidos, a otro distinto; y si no cumple ninguna de esas dos condiciones, no se ejecutará ningún fallback.
Diseñar la lógica de fallback así permite que el sistema actúe como lo haría el propio equipo de pagos “en directo”, no como una regla genérica aplicada a todos los casos. No se trata de realizar siempre reintentos, sino de decidir cuándo tiene sentido hacerlo y cuándo no, y dejar esa decisión integrada en la orquestación desde el primer momento.
Con este enfoque, las decisiones sobre fallbacks dejan de depender de cambios técnicos en backend. La lógica vive en la orquestación y puede ajustarse directamente por el equipo de pagos a medida que cambia la operativa, sin necesidad de modificar código.
De esta forma, los equipos de pagos pueden realizar ajustes sobre la lógica de fallback con rapidez. No solo porque la lógica de fallback sea “más flexible”, sino porque está diseñada para que este tipo de ajustes formen parte del funcionamiento normal de la operativa y no de un proceso excepcional.
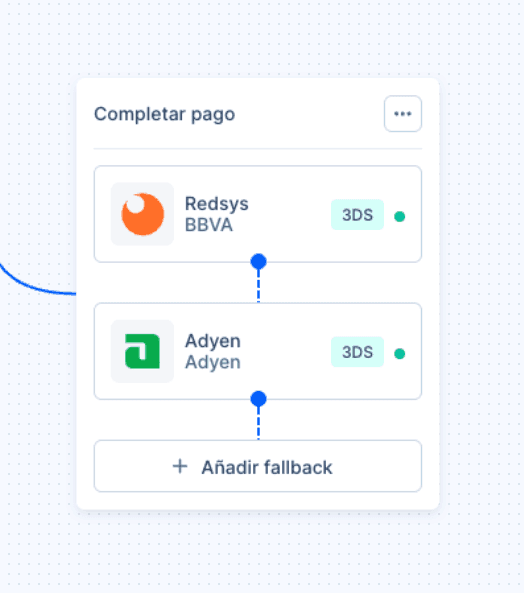
Ejemplo práctico de fallback
Imaginemos un ecommerce en España, que trabaja con dos procesadores. El primero aplica una comisión variable (un porcentaje del precio del carrito), y el segundo, además del porcentaje, cobra una comisión fija por transacción de X céntimos.
La empresa define su orquestación de la siguiente forma: los pagos con tarjeta se envían primero al procesador 1 y si fallan, se reintentan automáticamente por el procesador 2.
Sin embargo, como el procesador 2 cobra una comisión fija (además de la variable), en pedidos de importe bajo, por ejemplo inferiores a 10 €, este coste fijo puede hacer que el reintento no sea rentable. En esos casos, insistir con el segundo procesador no compensa.
Por eso, el fallback puede configurarse para que se active únicamente cuando el pedido sea igual o superior a 10 €. Así, la lógica no se aplica de forma indiscriminada sino alineada con la rentabilidad real de cada operación.
Este tipo de reglas se configuran desde el panel de Zru, sin necesidad de código.
Si quieres saber más cómo podemos ayudarte en la operativa diaria de pagos, contacta con nuestro equipo de Zru.
Producto
8
MINUTOS DE LECTURA
Cómo hemos diseñado la lógica de fallbacks en Zru
Tabla de contenido
El contexto detrás de los fallos en los pagos
Cuando un cliente intenta pagar y el pago falla, el motivo suele estar fuera del control del comercio: puede ser por ejemplo por falta de fondos, decisiones del banco emisor o incidencias técnicas del procesador. Son escenarios inevitables en cualquier sistema de pagos.
Lo que sí depende del negocio es cómo responder cuando ocurren estos errores de cobro. Los comercios con volumen, especialmente los que trabajan con orquestación, saben que pueden definir rutas alternativas para estos casos: rutas de “fallback” que se activan automáticamente cuando un procesador falla.
Sin embargo, añadir un fallback a la operativa de pagos puede ser complicado: hay que definir en qué caso se debe ejecutar la ruta, cuántos intentos se deben realizar en un mismo pago, así como implementar los cambios. Todo esto implica realizar configuraciones que pueden crear errores en la operativa.
Desde el equipo de producto de Zru, hemos trabajado sobre cómo abordar los fallbacks para que aporten valor a la operativa de los negocios, pero sin añadir fricción ni complejidad cuando se necesitan hacer cambios.
Hemos pensado los fallbacks como algo más que simples reintentos
Es corriente limitar los fallbacks únicamente a una regla binaria: si falla un proveedor, se cobra con otro. Sin embargo, esa lógica puede quedarse corta porque es demasiado genérica y no tiene en cuenta el contexto real de cada pago.
Desde Zru vemos a diario que no todos los fallos de pago significan lo mismo y no todos los reintentos van a aportar valor al comercio.
Lo más obvio son los errores “finales”, tipo “falta de fondos” o “tarjeta caducada”. En estos casos, no debemos seguir intentando el pago por otro procesador, ya que nos retornará el mismo error.
Pero también hay que tener en cuenta variables como la hora, día de la semana, el tipo de tarjeta, el país de emisión de la tarjeta, o incluso el importe del pago. Como cada negocio tiene sus particularidades, hay veces que aunque se reintente el pago, este no va a funcionar.
Nos parece importante que los negocios primero entiendan su operativa, tengan claro en qué casos merece la pena intentar el pago por otro procesador y creen las rutas en función de lo que saben. Para llegar a entender su operativa, muchas veces hay que primero validar hipótesis, y esto pasa por crear fallbacks de forma ágil: añadir, modificar y suprimir rutas cada vez que se necesite y sin depender del equipo de desarrollo y sin poner en peligro toda la operativa.
La decisión de diseño: lógica de fallback dentro de la orquestación
Desde el principio tuvimos claro que los fallbacks no podían tratarse como una funcionalidad aislada ni como una simple cadena de reglas independientes. Los fallos forman parte del comportamiento normal de un sistema de pagos y diseñarlos como algo excepcional sería un error.
Por eso decidimos integrar la lógica de fallback dentro de la propia orquestación. Tratar el fallo como una parte más del flujo nos permitió diseñar la lógica de fallback como una extensión natural de cómo se enrutan y procesan las transacciones.
Desde ese enfoque, la lógica de fallback tenía que ser capaz de recoger decisiones que los equipos de pagos ya toman en la práctica, aunque muchas veces de forma implícita o reactiva. Por ejemplo:
Cuándo tiene sentido reintentar un pago y cuándo insistir solo añade ruido operativo.
Qué ruta alternativa aplicar en un segundo intento, en función del contexto del pago.
Cuándo detener los reintentos para no entrar en bucles ni acumular fallos que perjudiquen la operativa con un proveedor.
¿Cómo funciona la lógica de fallback?
En una misma orquestación se pueden definir tantos fallbacks como tenga sentido en cada caso, y cada uno se ejecuta de forma independiente dentro del flujo.
Cada fallback se ejecuta o no en función de condiciones explícitas, definidas a partir de variables del propio pago. Son esas variables las que el sistema utiliza para aplicar la lógica definida por el equipo de pagos y ejecutar un reintento solo cuando tiene sentido.
Las condiciones pueden construirse, por ejemplo, a partir de:
Variables de la operación, como la moneda, el importe, el tipo de operación, si la operación es MOTO…
Variables del cliente, como el tipo de dispositivo o cierta información identificativa.
Variables de la tarjeta, como su tipo, marca o país de emisión.
Variables personalizadas, definidas por el propio comercio según su operativa.
Este enfoque hace que el fallback deje de ser un reintento automático y pase a ejecutarse sólo cuando las condiciones definidas por la operativa del negocio lo justifican. Por ejemplo, reintentar únicamente en los primeros días del mes o solo en las operaciones recurrentes.
Otra opción es diferenciar el comportamiento según el origen de la tarjeta. Si la tarjeta es europea, el fallback puede enrutar a un proveedor concreto; si es de Estados Unidos, a otro distinto; y si no cumple ninguna de esas dos condiciones, no se ejecutará ningún fallback.
Diseñar la lógica de fallback así permite que el sistema actúe como lo haría el propio equipo de pagos “en directo”, no como una regla genérica aplicada a todos los casos. No se trata de realizar siempre reintentos, sino de decidir cuándo tiene sentido hacerlo y cuándo no, y dejar esa decisión integrada en la orquestación desde el primer momento.
Con este enfoque, las decisiones sobre fallbacks dejan de depender de cambios técnicos en backend. La lógica vive en la orquestación y puede ajustarse directamente por el equipo de pagos a medida que cambia la operativa, sin necesidad de modificar código.
De esta forma, los equipos de pagos pueden realizar ajustes sobre la lógica de fallback con rapidez. No solo porque la lógica de fallback sea “más flexible”, sino porque está diseñada para que este tipo de ajustes formen parte del funcionamiento normal de la operativa y no de un proceso excepcional.
Ejemplo práctico de fallback
Imaginemos un ecommerce en España, que trabaja con dos procesadores. El primero aplica una comisión variable (un porcentaje del precio del carrito), y el segundo, además del porcentaje, cobra una comisión fija por transacción de X céntimos.
La empresa define su orquestación de la siguiente forma: los pagos con tarjeta se envían primero al procesador 1 y si fallan, se reintentan automáticamente por el procesador 2.
Sin embargo, como el procesador 2 cobra una comisión fija (además de la variable), en pedidos de importe bajo, por ejemplo inferiores a 10 €, este coste fijo puede hacer que el reintento no sea rentable. En esos casos, insistir con el segundo procesador no compensa.
Por eso, el fallback puede configurarse para que se active únicamente cuando el pedido sea igual o superior a 10 €. Así, la lógica no se aplica de forma indiscriminada sino alineada con la rentabilidad real de cada operación.
Este tipo de reglas se configuran desde el panel de Zru, sin necesidad de código.
Si quieres saber más cómo podemos ayudarte en la operativa diaria de pagos, contacta con nuestro equipo de Zru.





